Leyendo el periódico en R
Este post continúa en: iDEAL, la web para visualizar noticias del periódico IDEAL.
El periódico Ideal es el más leído en la provincia de Granada, con una penetración sobre el total de lectores de diarios (sea lo que sea eso) del 89%.
A principios de año, este diario adoptaba en su versión digital una medida llena de controversia: limitar el acceso a sus artículos, estableciendo un límite mensual de noticias. Al superar este límite, esto es todo lo que podemos ver en su página web:
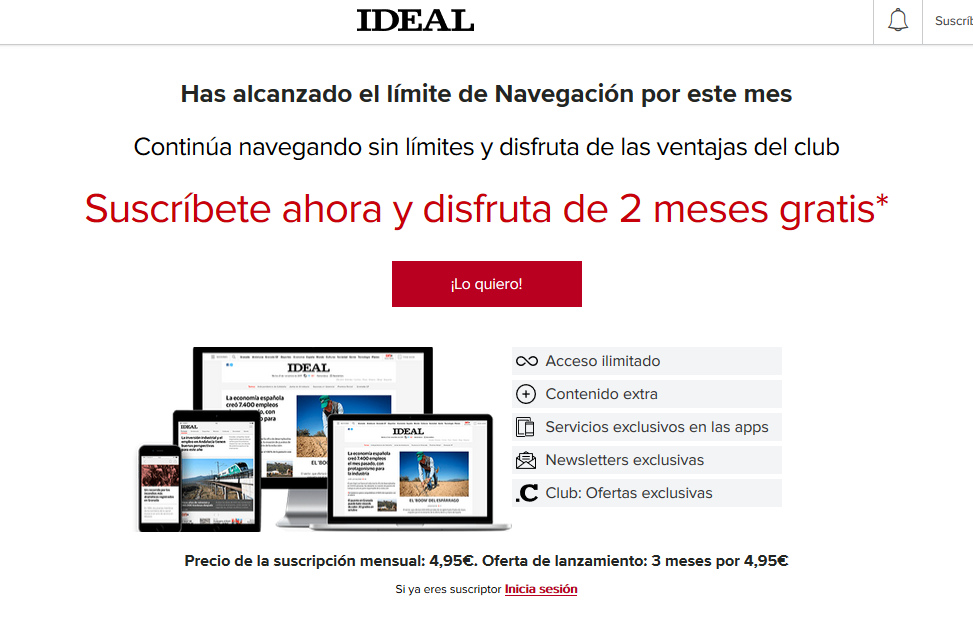
Esta decisión ha encajado muy bien en la sociedad granadina, que tiene claro que debe pagar para acceder a contenidos actuales de calidad.



En fin, cambiando totalmente de tema, me estoy iniciando en esto del web scraping, una técnica tan potente que pensé que estaba reservada sólo para unos pocos. Animado por este artículo, y siguiendo sus directrices, me he lanzado a la piscina con un pequeño script en R.
El código se alimenta del enlace de cualquier artículo de tu periódico granadino de referencia, y genera la noticia como salida, sin importar límites ni restricciones.
Aquí el código:
library(tidyverse)
library(xml2)
library(rvest)
url <- "http://www.ideal.es/granada/vota-granada-semifinal-20180328160038-nt.html"
titulo <- url %>% read_html() %>% html_nodes('h1') %>% html_text() %>% as.data.frame() %>% pull(1) %>% levels()
subtitulo_y_categoria <- url %>% read_html() %>% html_nodes('h2') %>% html_text() %>% as.data.frame() %>% pull(1) %>% levels()
subtitulo <- subtitulo_y_categoria[1]
categoria <- subtitulo_y_categoria[2]
cuerpo_original <- url %>% read_html() %>% html_nodes('p') %>% html_text()
# Ordenamos el cuerpo
cuerpo_recortado <- cuerpo_original[25:(length(cuerpo_original) - 1)]
cuerpo <- cuerpo_recortado[1]
for (i in 2:length(cuerpo_recortado)){
gsub(" ", "", cuerpo_recortado[i])
if(cuerpo_recortado[i]!="") cuerpo <- rbind(cuerpo, cuerpo_recortado[i])
}
imprimir_noticia <- function(n_titulo, n_subtitulo, n_categoria, n_cuerpo){
guiones <- replicate(50, "-") %>% paste(collapse = "")
cat(paste(c(guiones, "Título: ", n_titulo, guiones), collapse = "\n"))
cat(paste(c(guiones, "Subtítulo: ", n_subtitulo, guiones), collapse = "\n"))
cat(paste(c(guiones, "Categoría: ", n_categoria, guiones), collapse = "\n"))
cat(paste(c(guiones, "Cuerpo: ", n_cuerpo, guiones), collapse = "\n"))
}
imprimir_noticia(titulo, subtitulo, categoria, cuerpo)
Y aquí la salida:
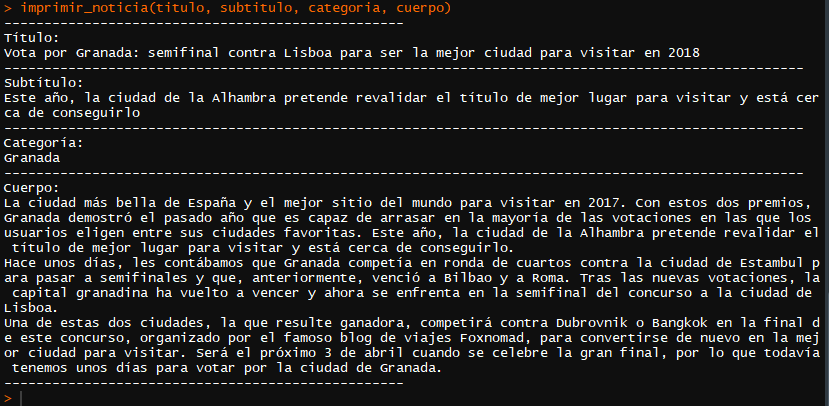
Este post continúa en: iDEAL, la web para visualizar noticias del periódico IDEAL.