Reglas de asociación (y detección de anomalías) con futbolistas usando R y estadísticas de FIFA
Las reglas de asociación son una técnica de aprendizaje no supervisado usada para extraer información relevante a partir de grandes conjuntos de datos. Sin entrar mucho en detalle, cada regla de asociación tiene vinculadas distintas medidas numéricas para determinar la relevancia de la regla. Su punto fuerte es la interpretabilidad, que cada vez tiene más importancia en el mundo del machine learning.
En esta publicación se aplican reglas de asociación sobre los datos de jugadores de FIFA 20.
Aprovecho la cuarentena provocada por la pandemia del coronavirus para adaptar para esta web un trabajo que realicé para la asignatura Minería de datos: Aprendizaje no supervisado y detección de anomalías del Máster de Ciencia de Datos de la Universidad de Granada.
Las reglas de asociación son una técnica de aprendizaje no supervisado usada para extraer información relevante a partir de grandes conjuntos de datos. Sin entrar mucho en detalle, cada regla de asociación tiene vinculadas distintas medidas numéricas para determinar la relevancia de la regla. Su punto fuerte es la interpretabilidad, que cada vez tiene más importancia en el mundo del machine learning.
Un ejemplo de regla de asociación es \(A \Rightarrow B\), donde \(A\) y \(B\) son conjuntos de items (itemsets) disjuntos. \(A\) y \(B\) son llamados, respectivamente, el antecedente y el consecuente de la regla.
Un ejemplo aplicado al mundo del fútbol podría ser:
$$ \text{Si un jugador es defensa} \Rightarrow \text{Su tiro es malo} $$
Esto no quiere decir que TODOS los defensas tiren mal, sino que en general cuando un jugador es defensa su tiro es malo. También podría leerse como “los defensas suelen tirar mal”.
1. Introducción al conjunto de datos
FIFA Ultimate Team es un modo de juego online de la serie de videojuegos de fútbol FIFA, al que juegan más de 10 millones de usuarios anualmente. En este modo de juego, los jugadores reales de fútbol se representan como cartas (o cromos) que pueden ser vendidos o comprados a cambio de dinero virtual. Las cartas virtuales de los jugadores tienen estadísticas asociadas (velocidad, pase, defensa, …) para hacer que sean parecidas a los jugadores reales.
 Ejemplo de equipo de FIFA Ultimate Team.
Ejemplo de equipo de FIFA Ultimate Team.
Futbin es una página web que permite conocer las estadísticas de los jugadores, así como su precio actual.
 Estadísticas y precios de Soldado en Futbin.
Estadísticas y precios de Soldado en Futbin.
El conjunto de datos que se analiza a continuación está obtenido mediante web scraping en Futbin y contiene todos los jugadores que tienen precio distinto de cero, no son porteros y tienen una puntuación media mayor o igual a 75. El web scraping se realizó el 20 de enero de 2020.
Tanto el conjunto de datos como el preprocesamiento realizado se omiten en esta publicación, aunque están disponibles en GitHub.
2. Carga de paquetes
library(dplyr) # Para usar pipes (%>%), select, filter, ...
library(arules) # Para trabajar con reglas de asociación
library(arulesViz) # Para visualizar reglas de asociación
3. Descripción del conjunto de datos
El conjunto de datos contiene información sobre 1841 jugadores de fútbol, en 16 variables. No hay ningún dato faltante.
# Número de filas y columnas
dim(futbin)
## [1] 1841 16
# Comprobación de datos faltantes
sum(is.na(futbin))
## [1] 0
Se describe a continuación el significado de cada variable:
-
name: Nombre del jugador.
-
rating: Puntuación global del jugador (de 75 a 99).
-
skills: Número de filigranas (de 1 a 5). Cuanto mayor es este número, más filigranas podrá hacer el jugador.
-
weak_foot: Número de pie malo (de 1 a 5). Cuanto mayor es este número, mejor jugará el jugador con su pie malo.
-
pac, sho, pas, dri, def, phy: Estadísticas de velocidad, disparo, pase, regate, defensa y físico del jugador (de 1 a 99).
-
hei: Altura del jugador, en centímetros.
-
popularity: Popularidad del jugador, según el voto (positivo o negativo) realizado por la comunidad de Futbin.
-
ps: Precio del jugador en la plataforma de PlayStation 4.
-
atacante, mediocentro, defensa: Indican la posición del jugador. Toman los valores “si” o “no”. Estas variables dummy se introducen para poder encontrar reglas de asociación con elementos negados (p.ej. defensa = no).
Se muestra la cabecera del conjunto de datos.
head(futbin, 10)
## name rating skills weak_foot pac sho pas dri def phy hei
## 1 Lionel Messi 94 4 4 87 92 92 96 39 66 170
## 2 Cristiano Ronaldo 93 5 4 90 93 82 89 35 78 187
## 3 Neymar Jr 92 5 5 91 85 87 95 32 58 175
## 4 Kevin De Bruyne 91 4 5 76 86 92 87 61 78 181
## 5 Eden Hazard 91 4 4 91 83 86 94 35 66 175
## 6 Mohamed Salah 90 4 3 93 86 81 89 45 74 175
## 7 Virgil van Dijk 90 2 3 77 60 70 72 90 86 193
## 8 Luka Modric 90 4 4 74 76 89 90 72 66 172
## 9 Giorgio Chiellini 89 2 3 68 46 58 62 90 82 187
## 10 Sergio Agüero 89 4 4 80 90 77 88 33 74 173
## popularity ps atacante mediocentro defensa
## 1 5267 958000 si no no
## 2 3393 920000 si no no
## 3 4662 762000 si no no
## 4 2493 189000 no si no
## 5 2164 199000 si no no
## 6 2909 150000 si no no
## 7 3627 490000 no no si
## 8 827 56000 no si no
## 9 326 41500 no no si
## 10 3293 78000 si no no
Eliminamos del conjunto el nombre de los jugadores, guardándolo previamente en una variable.
nombres_jugadores <- futbin$name
futbin <- futbin %>% select(-name)
4. Reglas de asociación
4.1. Preparación
Como vamos a usar el método a priori, las variables continuas deben convertirse a categóricas (factores), especificando los valores de corte. Otros métodos como MOPNAR realizan de manera autónoma los cortes que considera más oportunos en las variables numéricas.
# Puntuación global
futbin$rating <- ordered(cut(futbin$rating,
unique(quantile(futbin$rating)),
include.lowest = TRUE))
# Velocidad (análogo para disparo, pase, regate, defensa y físico)
futbin$pac <- ordered(cut(futbin$pac,
c(0, 65, 75, 80, 100),
labels = c("Muy bajo", "Bajo", "Alto", "Muy alto"),
include.lowest = TRUE))
# Altura
futbin$hei <- ordered(cut(futbin$hei, c(0, 177, 185, 205),
labels = c("Bajo", "Alto", "Muy alto"),
include.lowest = TRUE))
# Popularidad
futbin$popularity <- ordered(cut(futbin$popularity,
quantile(futbin$popularity),
include.lowest = TRUE))
# Precio
futbin$ps <- ordered(cut(futbin$ps,
quantile(futbin$ps),
include.lowest = TRUE))
# Pie malo
futbin$weak_foot <- factor(futbin$weak_foot,
levels = c("1", "2", "3", "4", "5"),
ordered = TRUE)
# Filigranas
futbin$skills <- factor(futbin$skills,
levels = c("1", "2", "3", "4", "5"),
ordered = TRUE)
Se convierte el conjunto de datos a tipo transacciones.
futbin_transacciones <- as(futbin, "transactions")
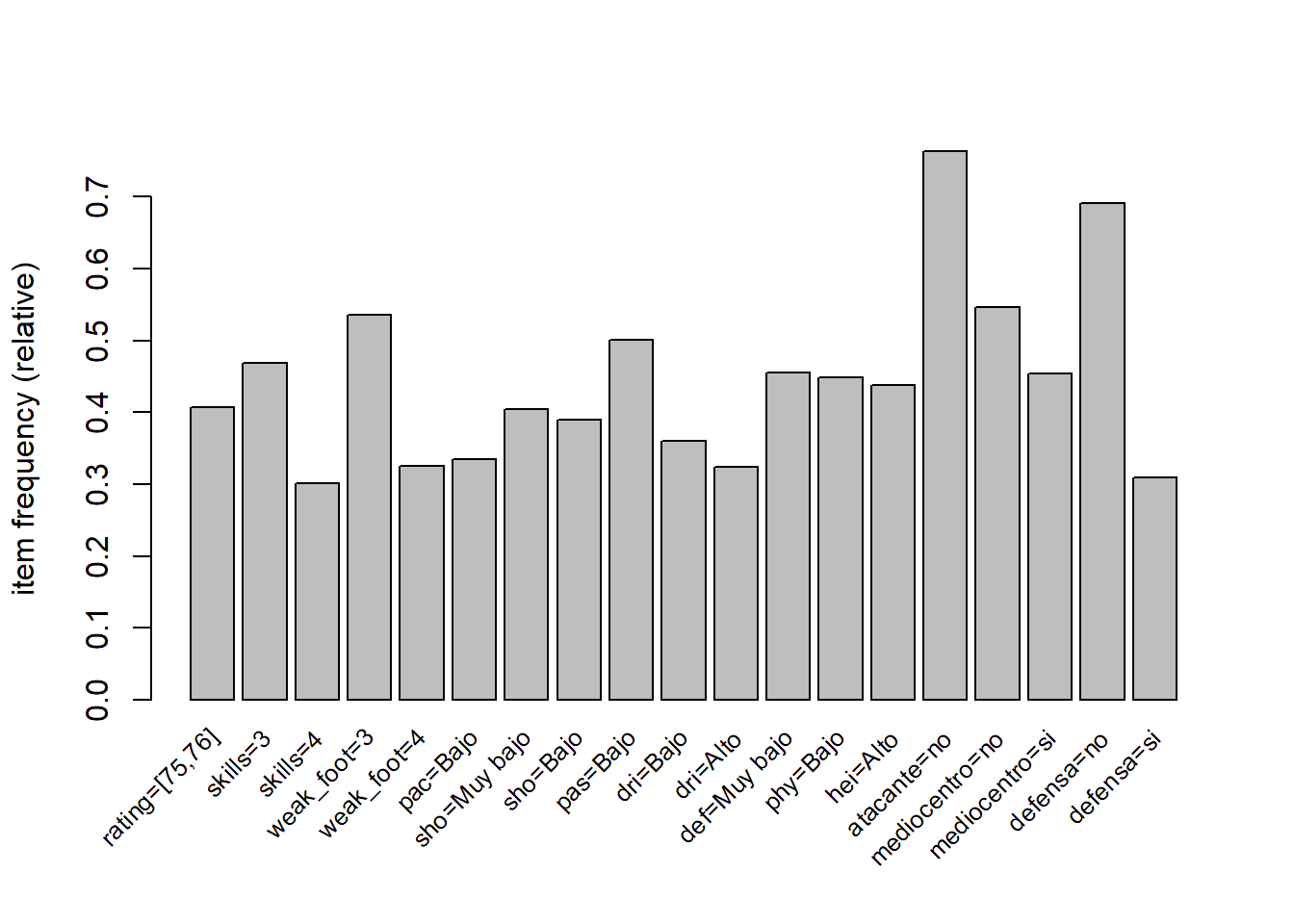
Se muestran gráficamente los items frecuentes (itemsets sólo de tamaño 1) con soporte mayor o igual del 30%.
itemFrequencyPlot(futbin_transacciones, support = 0.3, cex.names = 0.8)
4.2. Extracción de reglas con método a priori
Se realiza el método a priori de reglas de asociación, con 10% como mínimo de soporte de un itemset.
ifutbin_transacciones <- apriori(futbin_transacciones,
parameter = list(support = 0.1,
target = "frequent"),
control = list(verbose = FALSE))
# Se ordenan las reglas por el valor del soporte
ifutbin_transacciones <- sort(ifutbin_transacciones, by = "support")
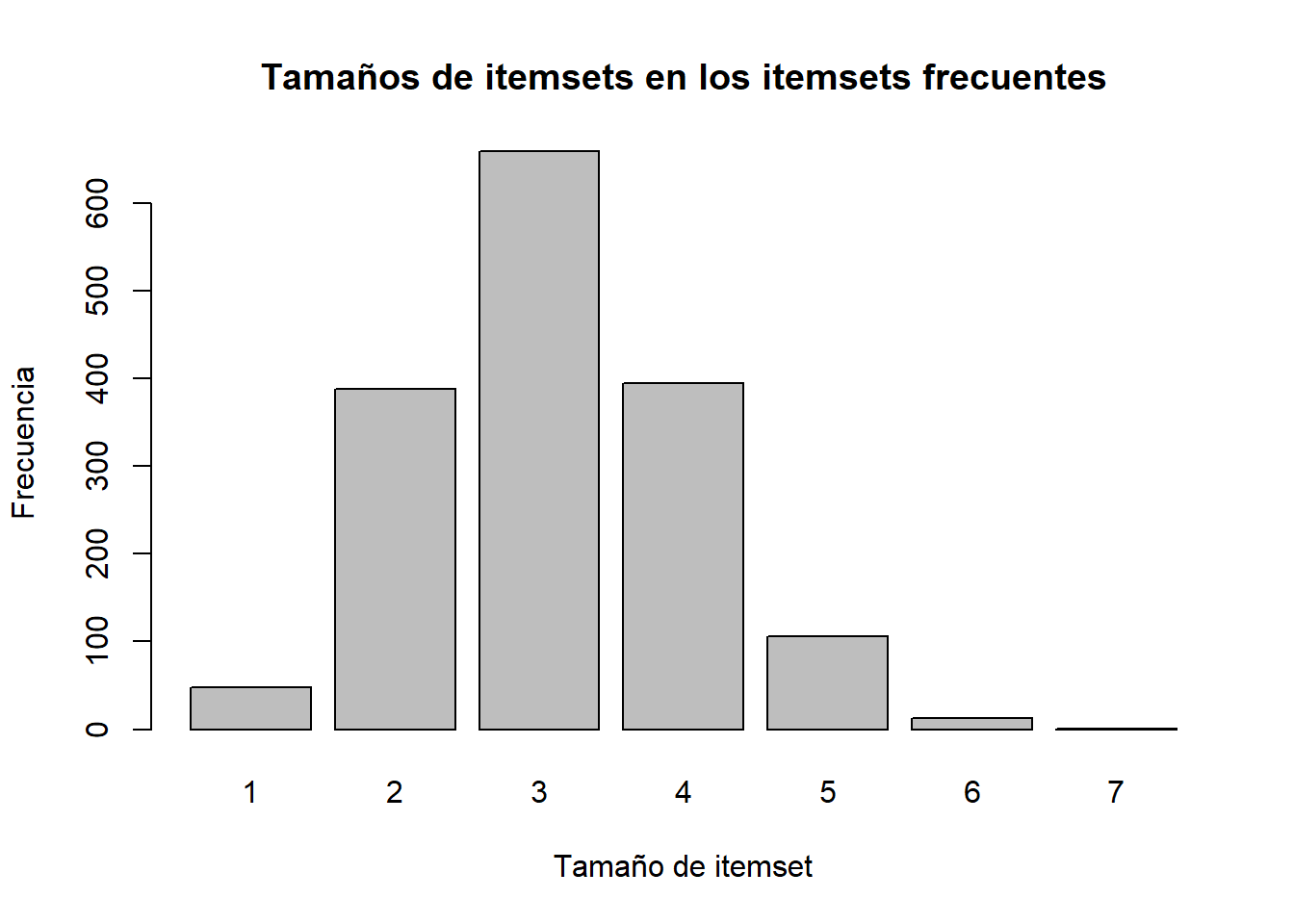
# Itemsets frecuentes
barplot(table(size(ifutbin_transacciones)),
xlab = "Tamaño de itemset", ylab = "Frecuencia",
main = "Tamaños de itemsets en los itemsets frecuentes")
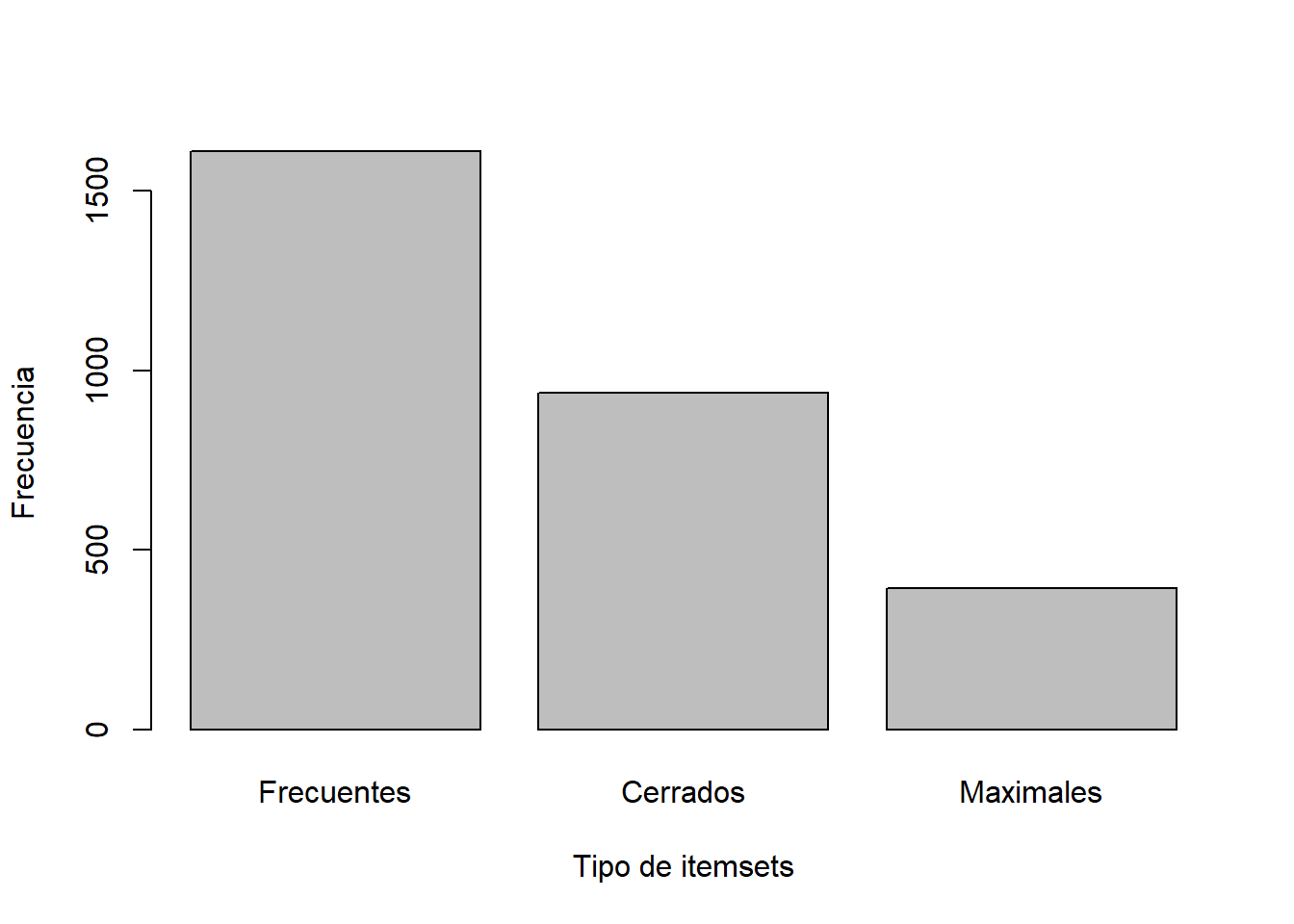
Se calculan los itemsets maximales y cerrados:
# Itemsets maximales
imaxfutbin_transacciones <- ifutbin_transacciones[is.maximal(ifutbin_transacciones)]
# Itemsets cerrados
iclofutbin_transacciones <- ifutbin_transacciones[is.closed(ifutbin_transacciones)]
Se muestran en un gráfico el número de itemsets frecuentes, cerrados y maximales:
barplot(c(Frecuentes = length(ifutbin_transacciones),
Cerrados = length(iclofutbin_transacciones),
Maximales = length(imaxfutbin_transacciones)),
ylab = "Frecuencia", xlab = "Tipo de itemsets")
Extracción de reglas: se exigen al menos dos elementos de la regla (antecedente y consecuente), un soporte mínimo del 10% y una confianza del 80%.
# Extracción de reglas
rules <- apriori(futbin_transacciones,
parameter = list(support = 0.1, confidence = 0.8, minlen = 2),
control = list(verbose = FALSE))
# Se ordenan las reglas por confianza
rulesSorted <- sort(rules, by = "confidence")
Se eliminan las reglas que son redundantes, esto es, reglas que están incluidas dentro de otras (antecedente de una regla incluida en el antecedente de otra regla).
# Matriz con todas las reglas como nombres de filas y columnas.
# is.subset comprueba para cada regla qué elementos son subconjuntos
# de todas las reglas una a una
subsetMatrix <- is.subset(rulesSorted, rulesSorted)
# Se filtran ahora los que han salido contenidas en 2 o más reglas
# porque como mínimo, cada regla es un subconjunto de sí misma
redundant <- colSums(subsetMatrix, na.rm = TRUE) >= 2
# Se eliminan las reglas redundantes
rulesPruned <- rulesSorted[!redundant]
Se eliminan ahora las reglas con confianza 1, que son fruto de que las variables atacante, mediocentro y defensa sean excluyentes.
# Se muestran las reglas con confianza 1
subset(rulesPruned, subset = confidence == 1) %>% inspect
## lhs rhs support confidence coverage
## [1] {atacante=si} => {mediocentro=no} 0.2368278 1 0.2368278
## [2] {atacante=si} => {defensa=no} 0.2368278 1 0.2368278
## [3] {defensa=si} => {mediocentro=no} 0.3096143 1 0.3096143
## [4] {defensa=si} => {atacante=no} 0.3096143 1 0.3096143
## [5] {mediocentro=si} => {defensa=no} 0.4535578 1 0.4535578
## [6] {mediocentro=si} => {atacante=no} 0.4535578 1 0.4535578
## lift count
## [1] 1.830020 436
## [2] 1.448466 436
## [3] 1.830020 570
## [4] 1.310320 570
## [5] 1.448466 835
## [6] 1.310320 835
# Se eliminan esas reglas
reglas_seleccionadas <- subset(rulesPruned, subset = confidence < 1)
Se seleccionan sólo aquellas reglas que tienen lift > 1, lo que implica una dependencia positiva entre antecedente y consecuente.
reglas_seleccionadas <- subset(reglas_seleccionadas, subset = lift > 1)
Se pueden examinar, por ejemplo, aquellas reglas en las que la altura de los jugadores aparece como antecedente.
reglas_altura <- subset(reglas_seleccionadas, subset = lhs %pin% "hei")
# Se muestra la regla con mayor confianza
inspect(head(reglas_altura, 1))
## lhs rhs support confidence coverage lift count
## [1] {hei=Bajo} => {defensa=no} 0.2466051 0.8239564 0.2992939 1.193473 454
Se podría concluir que los jugadores bajos no suelen ser defensas.
4.3. Selección de reglas relevantes
Se seleccionará un conjunto pequeño de reglas que puedan ser relevantes, en el sentido de que aporten información que no es obvia.
# Añadimos a las reglas varias medidas de interés:
mInteres <- interestMeasure(reglas_seleccionadas,
measure = c("gini", "chiSquared"),
transactions=futbin_transacciones)
quality(reglas_seleccionadas) <- cbind(quality(reglas_seleccionadas), mInteres)
Se buscan reglas con valores de soporte comprendidos entre 20% y 40% aproximadamente. Esto hará que se encuentren reglas que no son muy generales, y son lo suficientemente poco frecuentes como para que sean relevantes. Se seleccionan las 5 reglas de asociación que tienen mejor medida de interés gini.
subset(reglas_seleccionadas, subset = support > .2 & support < .4) %>%
head(by = "gini", n = 5) %>%
inspect
## lhs rhs support confidence coverage lift
## [1] {defensa=si} => {sho=Muy bajo} 0.2819120 0.9105263 0.3096143 2.253063
## [2] {atacante=si} => {def=Muy bajo} 0.2357414 0.9954128 0.2368278 2.184213
## [3] {pas=Muy bajo} => {mediocentro=no} 0.2346551 0.9250535 0.2536665 1.692866
## [4] {sho=Bajo} => {defensa=no} 0.3623031 0.9315642 0.3889191 1.349339
## [5] {skills=4} => {defensa=no} 0.2819120 0.9351351 0.3014666 1.354511
## count gini chiSquared
## [1] 519 0.23000828 879.2154
## [2] 434 0.18076588 670.8387
## [3] 432 0.09744229 361.9048
## [4] 667 0.07404027 318.8445
## [5] 519 0.05170417 222.6571
Por interpretar algunas reglas, se podría concluir que los defensas tienen disparo muy bajo (regla 1), los atacantes defienden muy mal (regla 2), y los jugadores con pase muy bajo no suelen ser centrocampistas (regla 3).
4.4. Visualización de las reglas de asociación
Se visualizan ahora las 10 reglas más relevantes encontradas, usando distintos métodos de visualización del paquete arulesViz.
# Tipo grafo
reglas_seleccionadas %>%
head(by = "gini", n = 10) %>%
plot(method = "graph")
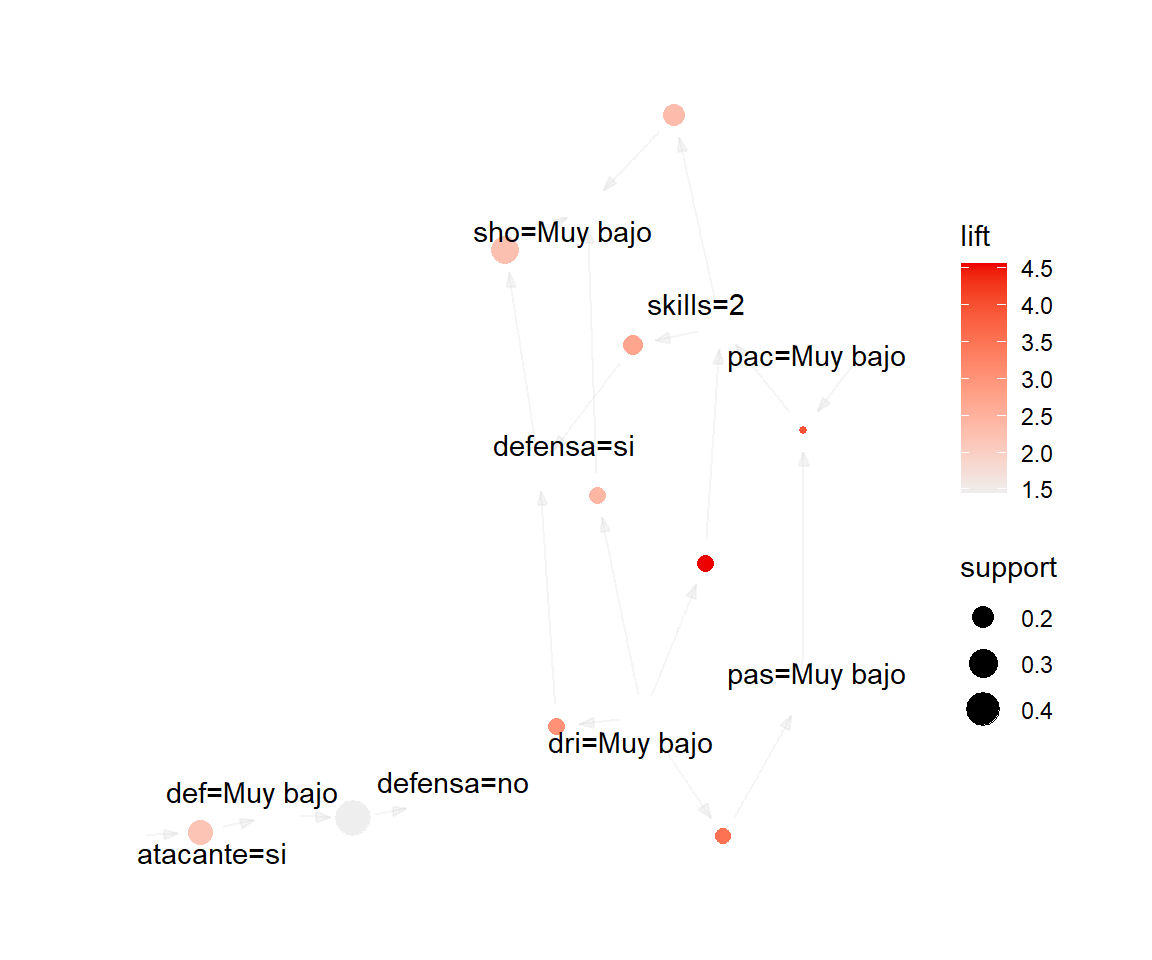
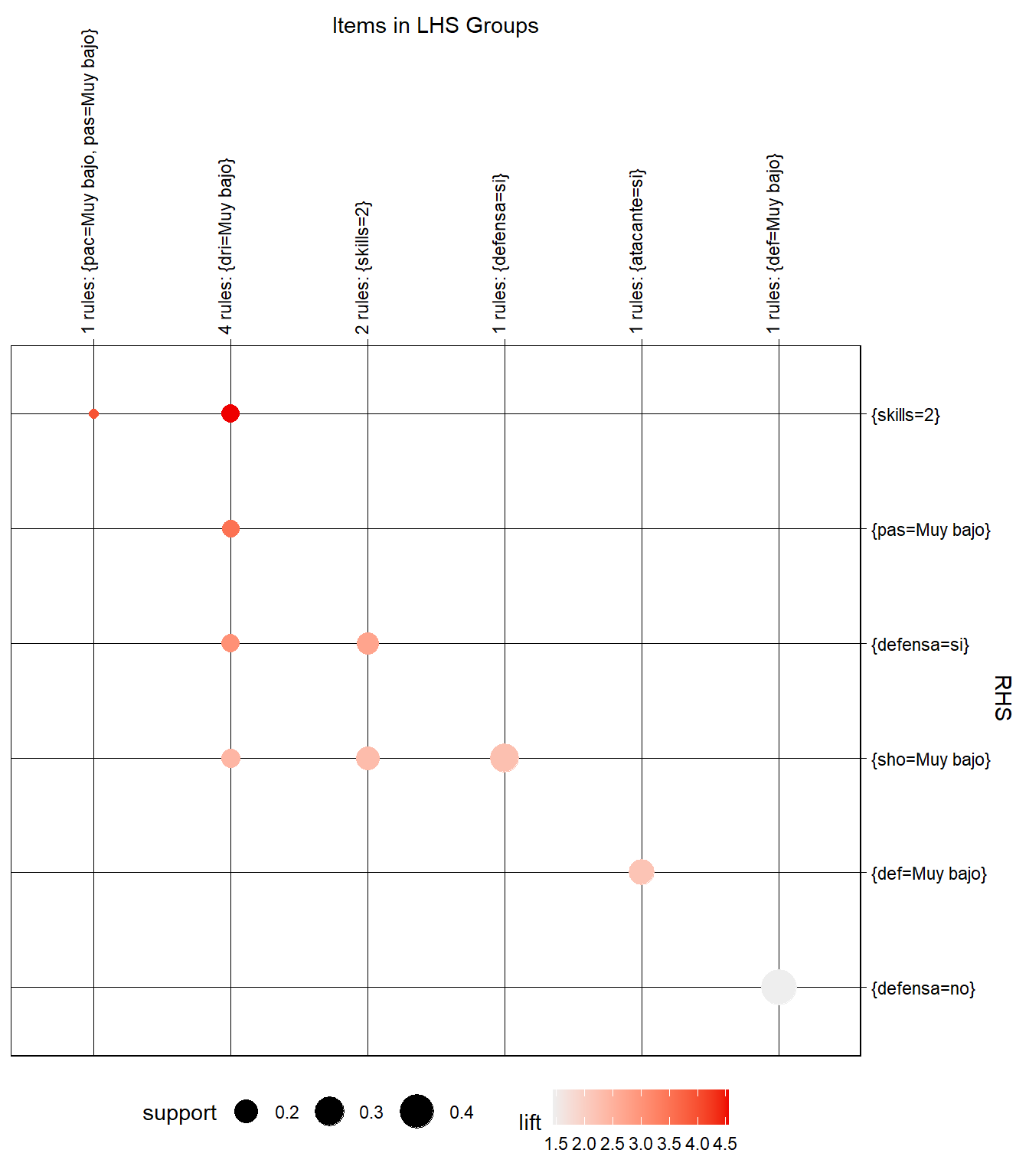
# Tipo matriz (Antecedente por columnas, consecuente por filas)
reglas_seleccionadas %>%
head(by = "gini", n = 10) %>%
plot(method = "grouped")
# Tipo coordenadas paralelas
reglas_seleccionadas %>%
head(by = "gini", n = 10) %>%
plot(method = "paracoord", reorder = TRUE)
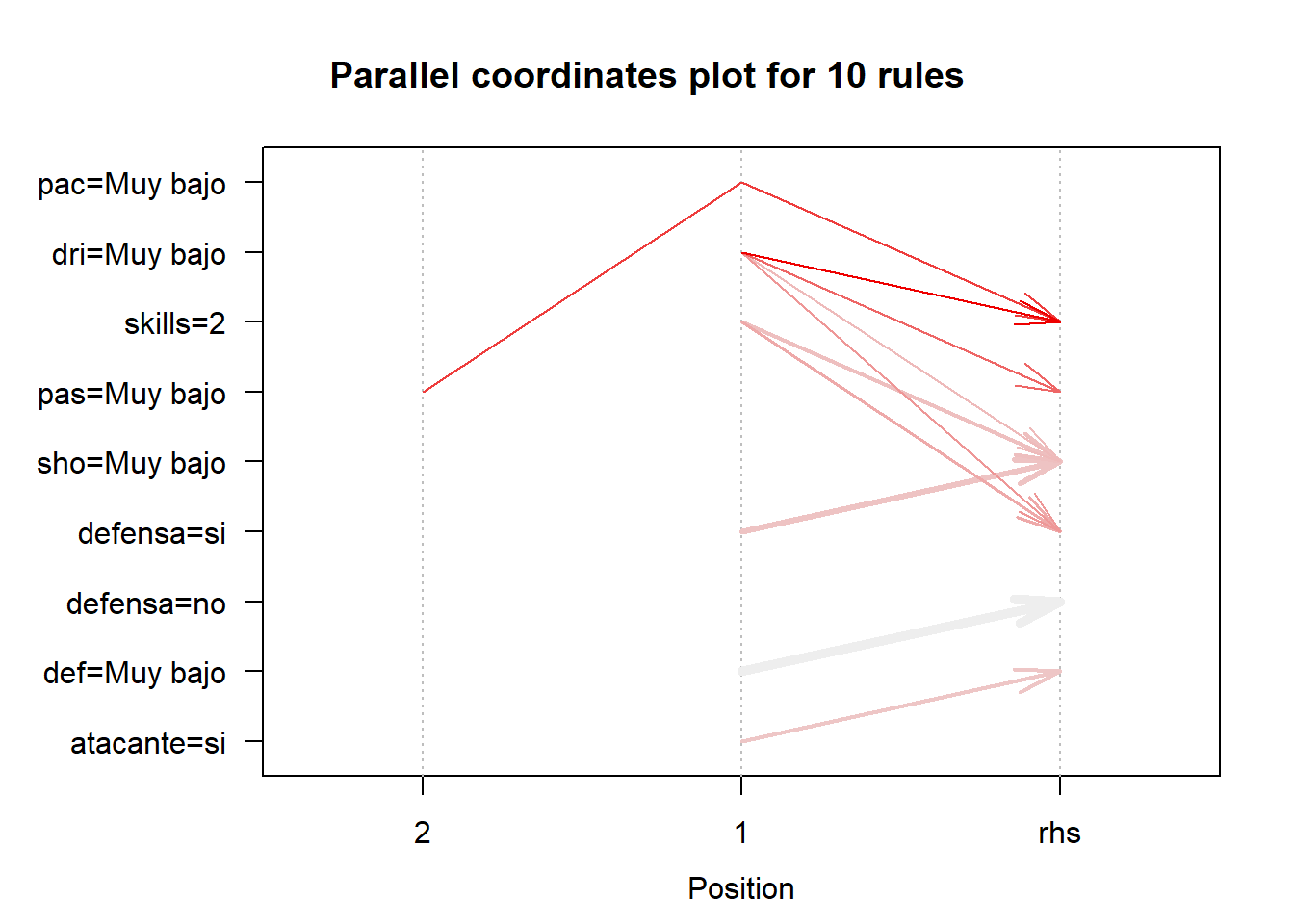
4.5. Detección de anomalías
Se mostrarán las reglas con mayor confianza para luego examinar los jugadores que no las cumplen, que podrían ser considerados excepciones o anomalías.
subset(reglas_seleccionadas, subset = support > .15 & support < .4) %>%
head(by = "confidence", n = 8) %>%
inspect
## lhs rhs support confidence coverage lift
## [1] {def=Bajo} => {atacante=no} 0.2721347 0.9980080 0.2726779 1.307710
## [2] {def=Alto} => {atacante=no} 0.2069527 0.9973822 0.2074959 1.306890
## [3] {atacante=si} => {def=Muy bajo} 0.2357414 0.9954128 0.2368278 2.184213
## [4] {sho=Alto} => {defensa=no} 0.1553504 0.9930556 0.1564367 1.438407
## [5] {skills=2} => {atacante=no} 0.2015209 0.9686684 0.2080391 1.269266
## [6] {phy=Muy bajo} => {defensa=no} 0.1933732 0.9621622 0.2009777 1.393659
## [7] {dri=Muy alto} => {defensa=no} 0.1591526 0.9482201 0.1678436 1.373464
## [8] {skills=2} => {sho=Muy bajo} 0.1950027 0.9373368 0.2080391 2.319405
## count gini chiSquared
## [1] 501 0.04135059 210.5961
## [2] 381 0.02872427 146.2910
## [3] 434 0.18076588 670.8387
## [4] 286 0.03397735 146.3189
## [5] 371 0.02218600 112.9919
## [6] 356 0.03715719 160.0125
## [7] 293 0.02681708 115.4842
## [8] 359 0.14937075 570.9754
# Se recuperan los nombres de los jugadores
futbin_w_names <- cbind(name = nombres_jugadores, futbin)
¿Hay atacantes que saben defender? (Reglas 1, 2 y 3)
futbin_w_names %>% filter(def == "Bajo" & atacante != "no") %>%
select(name)
## name
## 1 Kevin-Prince Boateng
futbin_w_names %>% filter(def == "Alto" & atacante != "no") %>%
select(name)
## name
## 1 Marcos Acuña
futbin_w_names %>% filter(atacante == "si" & def != "Muy bajo") %>%
select(name)
## name
## 1 Marcos Acuña
## 2 Kevin-Prince Boateng
Hay dos excepciones: Kevin-Prince Boateng y Acuña, dos atacantes que tienen buenas estadísticas defensivas. De hecho, aunque Boateng aparezca como delantero, durante gran parte de su carrera ha jugado de centrocampista, como demuestra el hecho de que desde FIFA 10 hasta FIFA 19 siempre ha aparecido como centrocampista. El caso de Acuña es similar: aunque en el juego aparece como extremo izquierdo, suele jugar de interior izquierdo, carrilero o incluso lateral.
¿Hay defensas con buen disparo? (Regla 4)
futbin_w_names %>%
filter(defensa == "si" & sho == "Alto") %>%
select(name)
## name
## 1 Alessandro Florenzi
## 2 Vieirinha
Florenzi (70 goles en 391 partidos) y Vierinha (51 goles en 413 partidos) son de hecho los dos defensas con mejor tiro en el videojuego, y sus estadísticas reales de goles son excelentes para tratarse de defensas.
¿Hay delanteros con pocas filigranas? (Regla 5)
futbin_w_names %>%
filter(atacante == "si" & skills == "2") %>%
select(name, hei, pac)
## name hei pac
## 1 Edin Džeko Muy alto Muy bajo
## 2 Diego Costa Muy alto Bajo
## 3 Luuk de Jong Muy alto Muy bajo
## 4 Bas Dost Muy alto Muy bajo
## 5 Troy Deeney Alto Muy bajo
## 6 Glenn Murray Alto Muy bajo
## 7 Chris Wood Muy alto Bajo
## 8 Klaas-Jan Huntelaar Muy alto Muy bajo
## 9 Christian Benteke Muy alto Muy bajo
## 10 Charlie Austin Muy alto Muy bajo
## 11 Andy Carroll Muy alto Muy bajo
## 12 Stefano Okaka Muy alto Muy bajo
Son delanteros toscos, y en su mayoría muy altos, superando algunos los 190 centímetros.
¿Hay jugadores con físico muy bajo que sean defensas? (Regla 6)
futbin_w_names %>%
filter(phy == "Muy bajo" & defensa == "si") %>%
select(name) %>%
t %>%
as.vector
## [1] "Aarón Martín" "Emerson" "Danilo" "Vieirinha"
## [5] "Júnior Caiçara" "Phil Jagielka" "Diogo Viana" "Raúl Navas"
## [9] "Leighton Baines" "Álex Moreno" "Scott Dann" "Yuto Nagatomo"
## [13] "Zaldúa" "Martín"
Son jugadores en su mayor parte laterales, que no necesitan una gran corpulencia para defender.
¿Hay defensas que regatean muy bien? (Regla 7)
futbin_w_names %>%
filter(dri == "Muy alto" & defensa == "si") %>%
select(name) %>%
t %>%
as.vector
## [1] "Jordi Alba" "Joshua Kimmich" "Marcelo" "Carvajal"
## [5] "João Cancelo" "Alex Telles" "Grimaldo" "Ricardo Pereira"
## [9] "Nélson Semedo" "Ismaily" "Bernat" "Kwadwo Asamoah"
## [13] "Rubén Peña" "Mitchell Weiser" "Youcef Atal" "Vieirinha"
La mayoría son laterales de primer nivel mundial: Jordi Alba, Marcelo, …
¿Hay jugadores con pocas filigranas que no tiren muy mal? (Regla 8)
futbin_w_names %>%
filter(skills == "2" & sho != "Muy bajo") %>%
select(name) %>%
t %>%
as.vector
## [1] "Casemiro" "Blaise Matuidi" "Edin Džeko"
## [4] "Sami Khedira" "Diego Costa" "Luuk de Jong"
## [7] "Bas Dost" "Lukasz Piszczek" "Luka Milivojevic"
## [10] "Fabian Schär" "Andreas Samaris" "Leander Dendoncker"
## [13] "Manu García" "Troy Deeney" "Mikel San José"
## [16] "Glenn Murray" "Chris Wood" "Klaas-Jan Huntelaar"
## [19] "Marco Höger" "Oliver Norwood" "Christian Benteke"
## [22] "Charlie Austin" "Andy Carroll" "Stefano Okaka"
Son jugadores torpes con el balón pero con buen tiro, algunos por ser delanteros rematadores (Diego Costa, Andy Carroll) y otros por ser centrocampistas o defensas con llegada desde fuera del área, o grandes cabeceadores (Casemiro, Khedira, San José).
- Posted on:
- April 5, 2020
- Length:
- 13 minute read, 2751 words