Descargando datos sobre canciones de Spotify con R: Los Planetas
Además de recoger los nombres de las canciones y su duración, Spotify analiza de manera interna las canciones de su plataforma, asignándoles valores de las siguientes cualidades: positiva, bailable, enérgica, acústica, en directo y hablada. Una descripción más completa sobre estas características (así como otras variables que recogen) se puede encontrar en la web de Spotify.
En esta publicación voy a mostrar cómo usar R para descargar metadatos de canciones de Spotify.
Preparación
{RSpotify} es un paquete de R que permite interactuar con la API de Spotify. Para ello, necesitarás dos pasos previos:
-
Conseguir un token de autenticación de Spotify. Se puede hacer a través de este enlace.
-
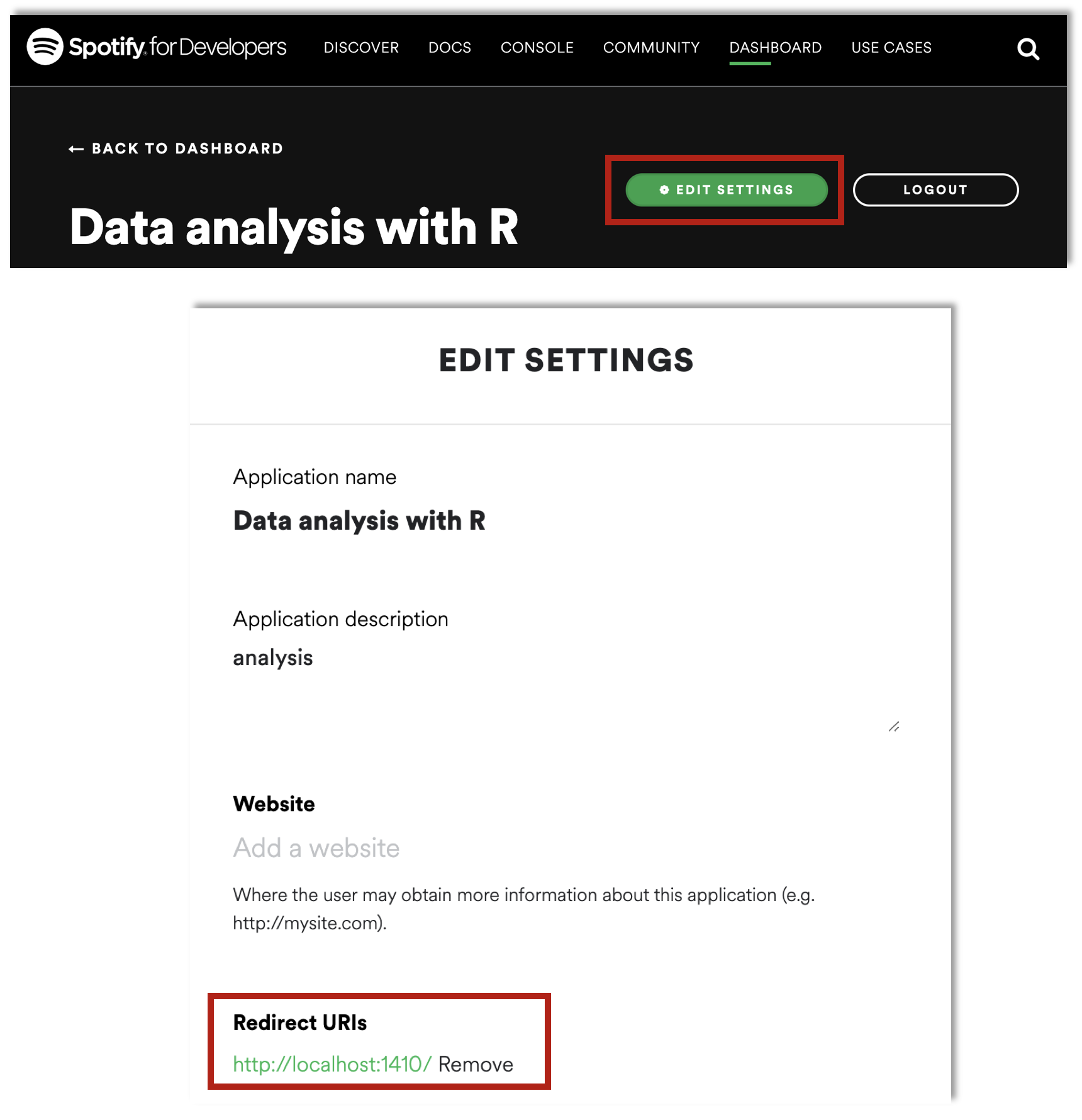
Añadir la URL
http://localhost:1410/en la web de Spotify for Developers (apartado Edit Settings -> Redirect URIs)
Código
Descargaré para este ejemplo la información que guarda Spotify de todas las canciones de Los Planetas. Si quieres acceder al código completo que he usado para esta publicación, está disponible en este enlace.
Para empezar, cargamos los paquetes {Rspotify} y {dplyr} y nos identificamos con el nombre y token de la aplicación que hemos creado en Spotify (app_name, client_id y client_secret).
# ----- Carga de paquetes -----
# install_github("tiagomendesdantas/Rspotify")
library(Rspotify)
library(dplyr)
# ----- Tokens para la aplicación de Spotify -----
app_name <- "[NOMBRE DE LA APLICACIÓN EN SPOTIFY]"
client_id <- "[CLIENT_ID DE LA APLICACIÓN EN SPOTIFY]"
client_secret <- "[CLIENT_SECRET DE LA APLICACIÓN EN SPOTIFY]"
keys <- spotifyOAuth(app_name, client_id, client_secret)
Una vez autenticados por Spotify, ya podemos hacer llamadas a su API. Conseguimos en primer lugar el ID del artista.
# Encontrar ID del artista
searchArtist("Los Planetas", token = keys)
# Definir el ID del artista adecuado
# (pueden salir artistas con nombres similares)
id <- "0N1TIXCk9Q9JbEPXQDclEL"
Descargamos a continuación la información de todos los discos:
# Extraer discos
discografia <- getAlbums(artist_id = id, token = keys) %>%
# Quitar duplicados
group_by(name) %>% summarise(id = min(id)) %>%
# Quitar edición especial y reediciones/recopilatorios
filter(! name %in% c("Zona Temporalmente Autónoma (Edición Especial)",
"Canciones para una Orquesta Química",
"Principios Basicos De Astronomia"))
# Poner tildes a algunos discos
discografia$name[6] <- "Una Ópera Egipcia"
discografia$name[7] <- "Una Semana En El Motor De Un Autobús"
Descargamos ahora, disco a disco, la información de sus canciones.
# Se extrae la lista de canciones de cada disco
for(i in discografia$id){
# Se conserva el ID del disco para más adelante
album_name <- discografia$name[match(i, discografia$id)]
if(i == discografia$id[1]) canciones_spotify <- cbind(getAlbum(album_id = i, token = keys), album = i, album_name)
else canciones_spotify <- rbind(canciones_spotify, cbind(getAlbum(album_id = i, token = keys), album = i, album_name))
}
canciones_spotify <- as_tibble(canciones_spotify)
# Se extraen las características de todas las canciones
for(cancion in canciones_spotify$id){
if(cancion == canciones_spotify$id[1]) canciones <- getFeatures(track_id = cancion, token = keys)
else canciones <- rbind(canciones, getFeatures(track_id = cancion, token = keys))
}
canciones <- as_tibble(canciones)
Para finalizar se realiza un preprocesamiento de los datos para que estén listos para el posterior análisis.
# Pasar listas a vectores
canciones_spotify$id <- unlist(canciones_spotify$id)
canciones_spotify$name <- unlist(canciones_spotify$name)
# Añadir disco a las canciones
canciones <- merge(canciones_spotify, canciones, by = "id") %>%
as_tibble() %>%
select(id, name, album_id = album, album = album_name,
duration = duration_ms.y, tempo, valence,
danceability, energy, acousticness,
instrumentalness, liveness, speechiness) %>%
# Quitar duplicado de "Desorden"
# (son dos mezclas de la misma canción, se quita la versión de 4:03)
# Más info en: https://es.wikipedia.org/wiki/Super_8_(%C3%A1lbum)#Lista_de_canciones
filter(id != "2phdCylIBc8WjK7llBajFi")
head(canciones)
# Comprobación de duplicados
length(canciones$name) == length(unique(canciones$name))
# Pasar a porcentajes las características de Spotify
canciones[7:13] <- round(canciones[7:13] * 100, 1)
# Convertir la duración a segundos
canciones$duration <- round(canciones$duration / 1000, 1)
# Redondear tempo a 1 decimal
canciones$tempo <- round(canciones$tempo, 1)
Y para acabar, se exportan los datos:
save(canciones, file = "canciones.RData")
head(canciones)
## # A tibble: 6 x 13
## id name album_id album duration tempo valence danceability energy
## <chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 02jXZfT8IjNmd~ Isla~ 1khQHoH~ Zona~ 423. 118. 12.8 36.4 51.6
## 2 0e8EpWgw3MmmY~ La M~ 4qNag8c~ Pop 343 133. 53 25.5 93
## 3 0eOEe1eGVaxNh~ Corr~ 2yr7ln7~ Encu~ 278. 123. 54.7 52.3 78.3
## 4 0h84bQDr2i0uL~ Entr~ 165G43f~ La L~ 163. 138. 39.6 34.2 65.7
## 5 0JJFhZAHf8p5Q~ 8 4qNag8c~ Pop 236. 138. 73.5 48.3 85.7
## 6 0K7drrEz6pKMw~ 124 26hZrPW~ Los ~ 246. 112 82.2 36.6 94.9
## # ... with 4 more variables: acousticness <dbl>, instrumentalness <dbl>,
## # liveness <dbl>, speechiness <dbl>
Tabla interactiva con los datos descargados
Voy a utilizar el paquete {DT} para mostrar una tabla con la información extraída de las canciones, que permite ordenar por columnas y buscar canciones concretas.
library(DT)
# Seleccionar variables relevantes
df <- canciones %>% select(-id, -album_id, -speechiness)
# Tabla interactiva
datatable(df,
rownames = F,
colnames = c("Canción", "Disco", "Duración(s)", "Tempo",
"Positiva(%)", "Bailable(%)", "Enérgica(%)",
"Acústica(%)", "Instrumental(%)", "Directo(%)")) %>%
# Añadir gráfico de barras a las variables que son porcentajes
formatStyle(names(df)[5:length(df)],
background = styleColorBar(range(df[5:length(df)]), "lightblue")) %>%
# Reducir tamaño de texto
formatStyle(names(df), fontSize = "11px", lineHeight = "95%")
Resultados
En las siguientes imágenes resumo algunos de los resultados obtenidos sobre las canciones de Los Planetas:
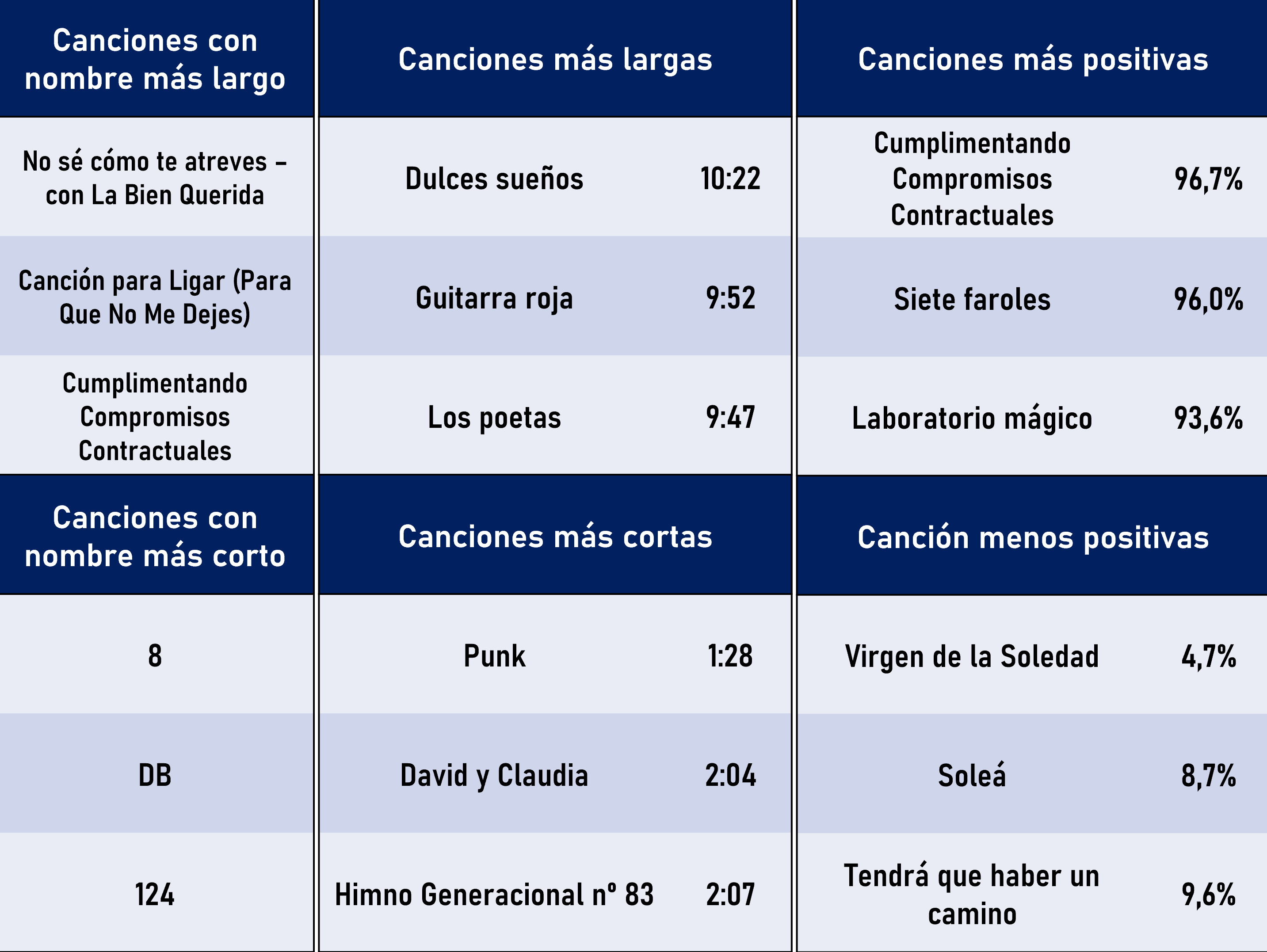
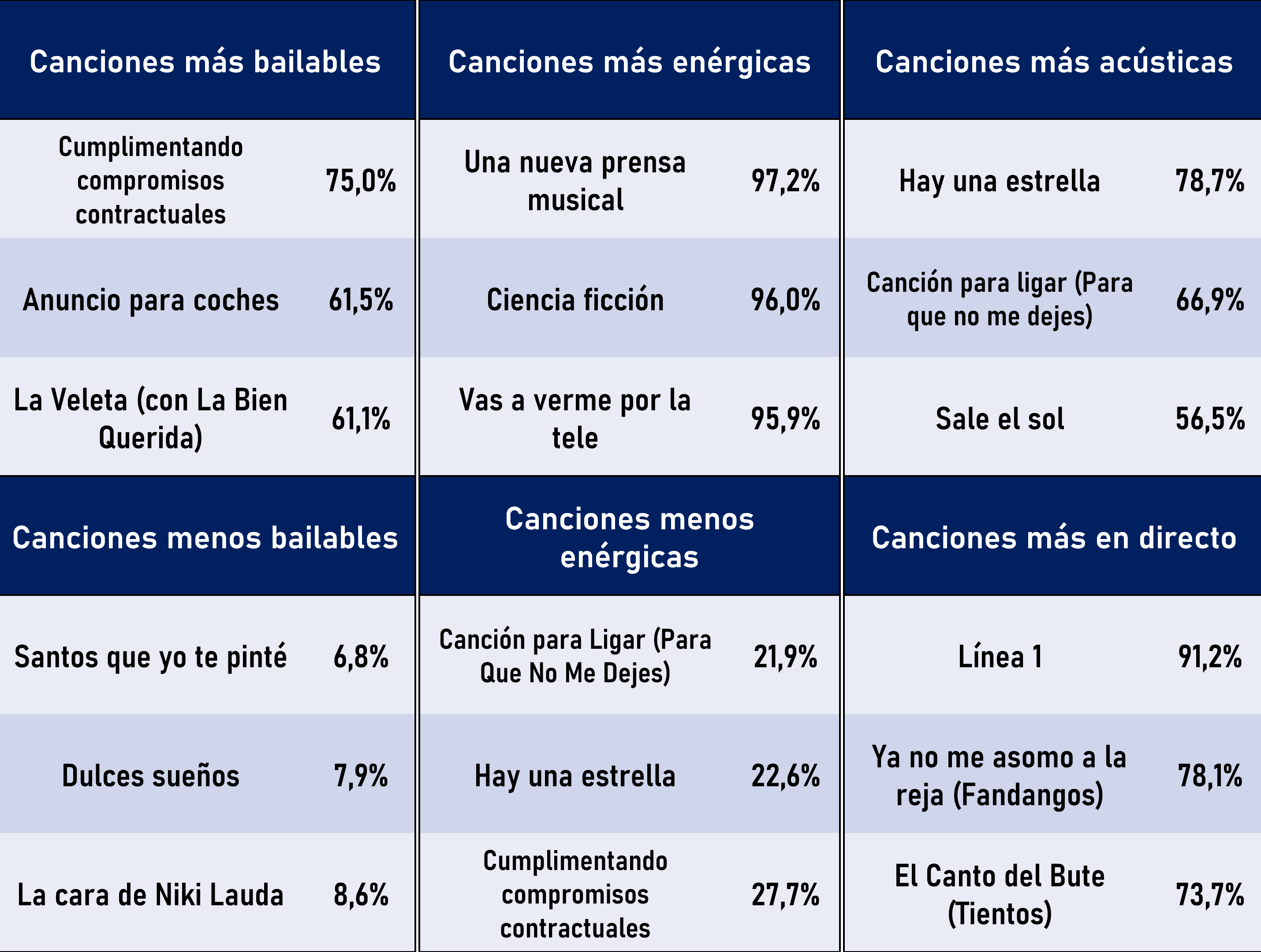
Cualidades de algunas canciones
Profundizando algo más, se puede describir cada canción de manera individual en base a sus características. El siguiente GIF muestra las distintas cualidades de tres canciones concretas de Los Planetas: “Un buen día,” “Línea 1” y “Pesadilla en el parque de atracciones.”
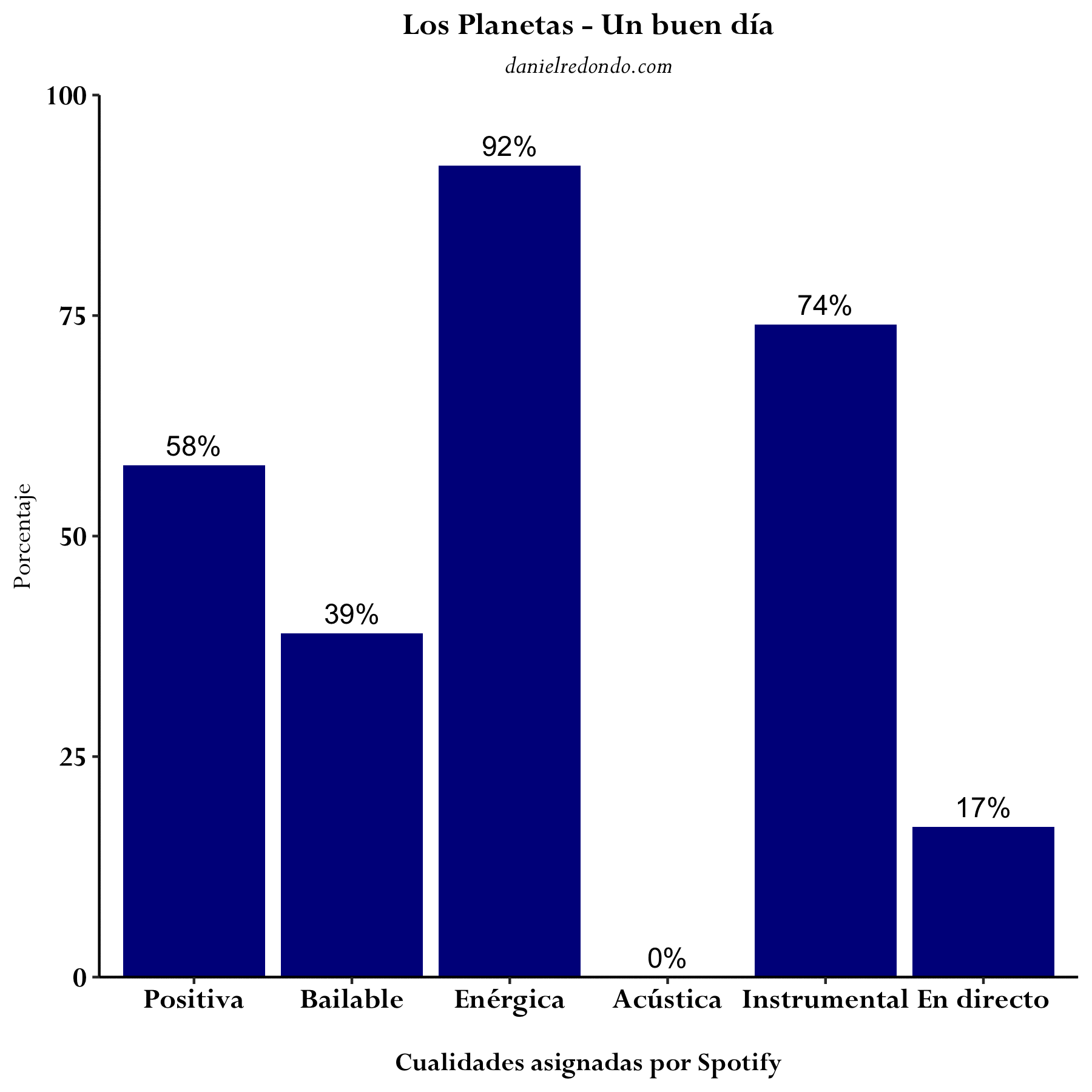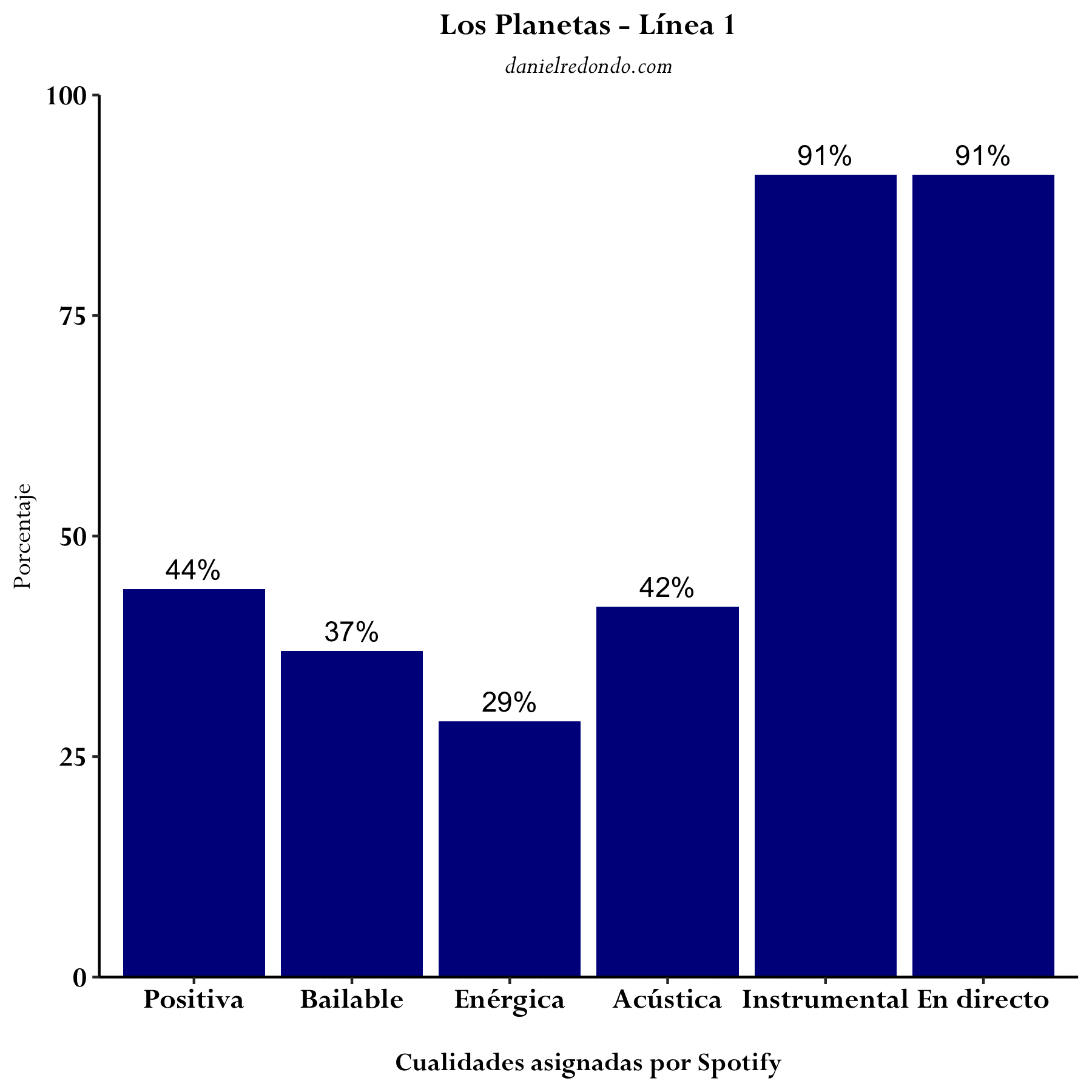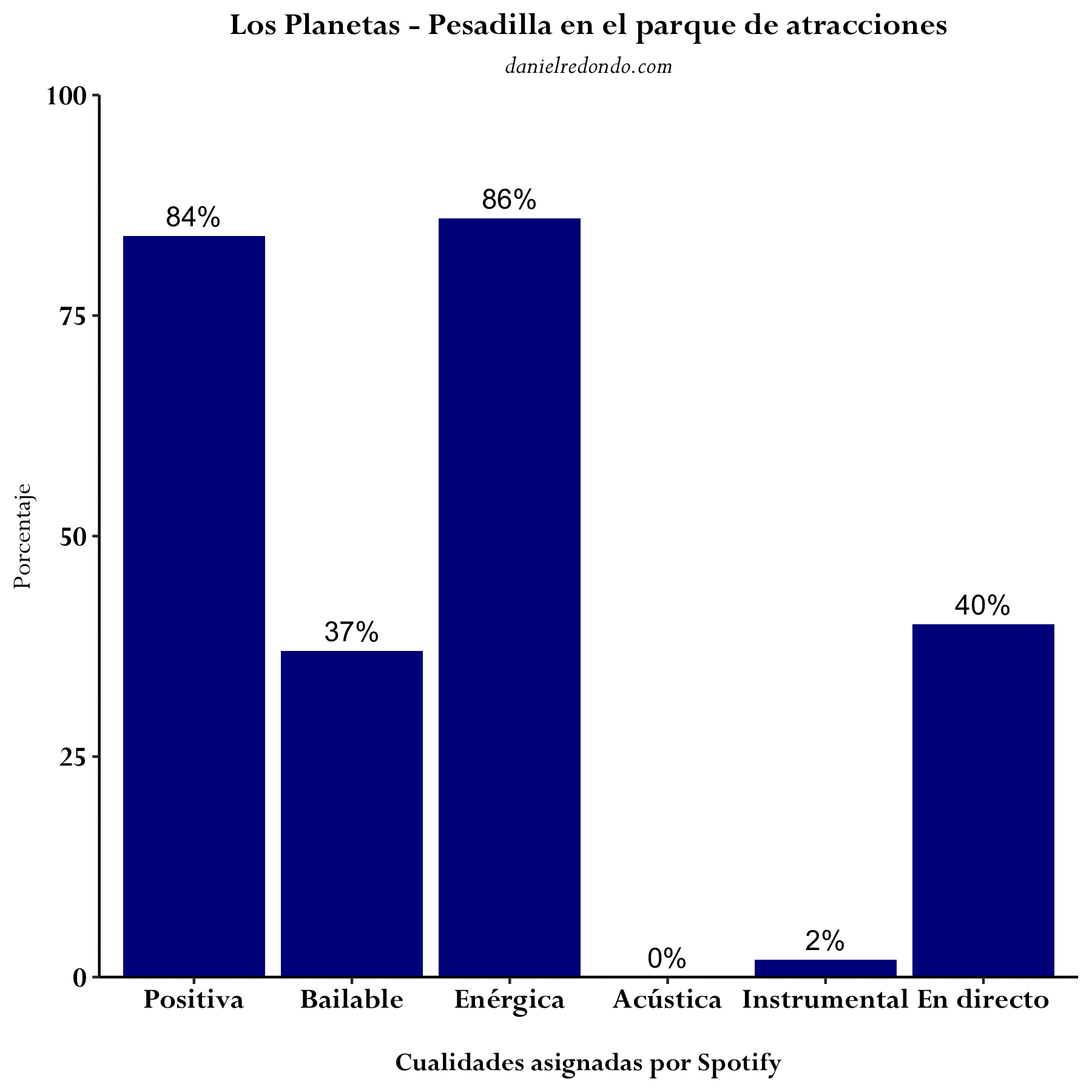
He escrito una función en R que, dado el ID de la canción de Spotify, genera un gráfico idéntico a los anteriores.
Cualidades medias por discos
Y para acabar, en este gráfico interactivo se muestran las cualidades medias de las canciones para cada disco de Los Planetas.
En la siguiente publicación he utilizado estos datos para aplicar análisis de componentes principales (PCA).
Todo el código de R utilizado para esta publicación está disponible en este repositorio de GitHub. ¡Os invito a analizar las canciones de vuestros grupos favoritos!
- Posted on:
- August 27, 2021
- Length:
- 5 minute read, 967 words